One of the planned outputs for LatinNow is a publicly accessible GIS. This will be an easily navigable web-based interface (similar to tools produced by ORBIS or EngLaId), which will display, amongst other things, inscriptions of the north-western Roman provinces as points on a map. Users will be able to search for inscriptions, filtering the data by e.g. location, date, and inscribed material; and then be able to display the text of the target inscription.
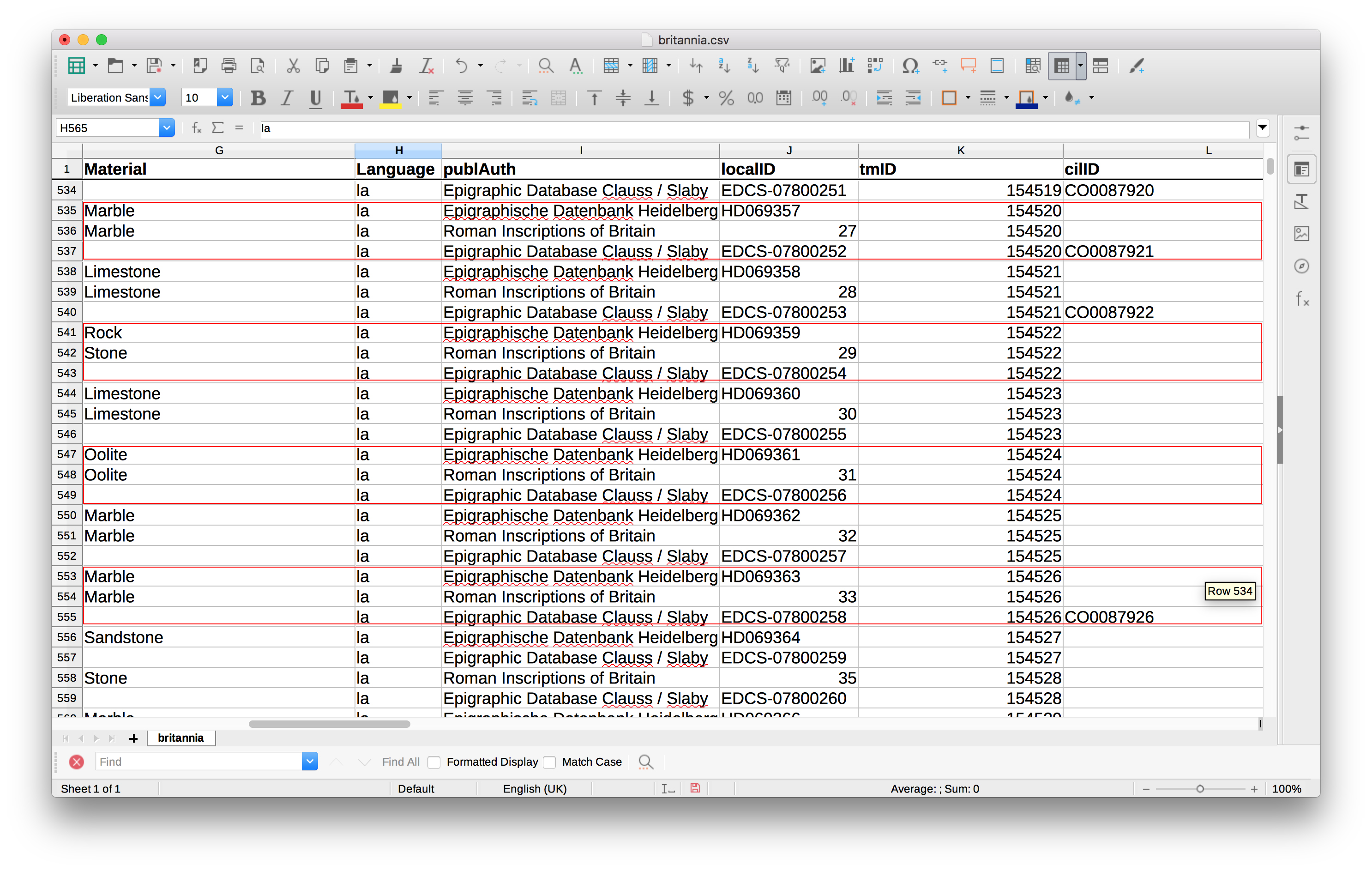
The data for the Latin and Greek inscriptions in this GIS comes from EAGLE, and comprises over 180,000 inscriptions marked up (largely through an automated process) with EpiDoc. With the help of our European Special Advisor Pietro Liuzzo, we obtained a collection of all the EAGLE files relevant to our provinces of study — i.e. the collection of ‘Classical’ language inscriptions which we can use in our GIS. However, it is not simply a case of dumping these files straight into a GIS: the collection contains multiple appearances of the same inscription in different Epigraphic corpora (e.g. Epigraphic Database Clauss Slaby; Epigraphische Datenbank Heidelberg; Roman Inscriptions of Britain), or even different editions/readings of the same text from the same corpus. We have also identified some problems with the automatic EpiDoc’ing process. For example, some of the files were EpiDoc’ed without geographic co-ordinates — essential references for displaying the data geospatially — and much work is therefore needed to make the data ‘GIS’ ready, either by manually adding in co-ordinates or linking the data up with Pleiades (where possible). The GIS team is currently dedicating most of its time to the cleaning and processing of the material in this way.
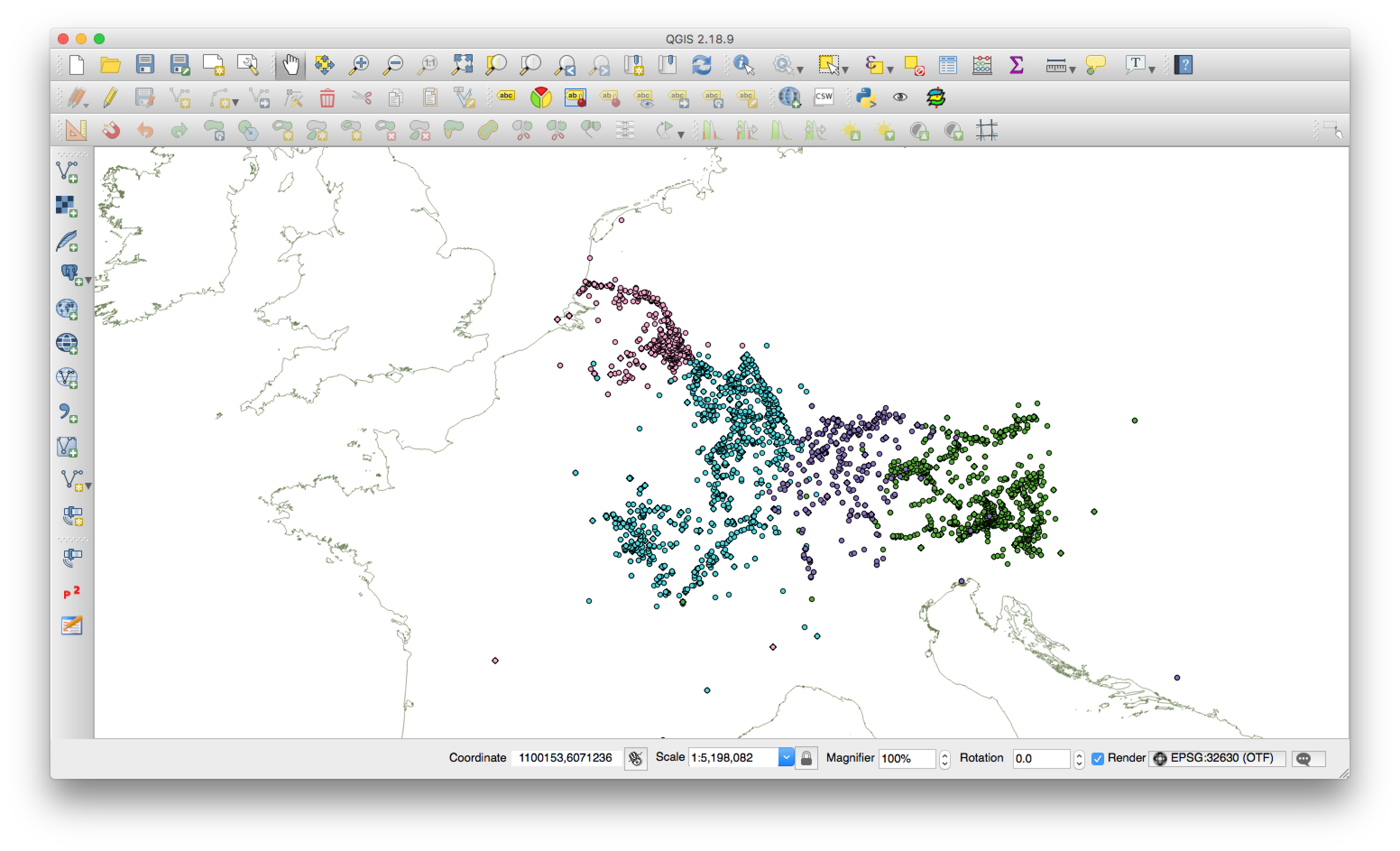
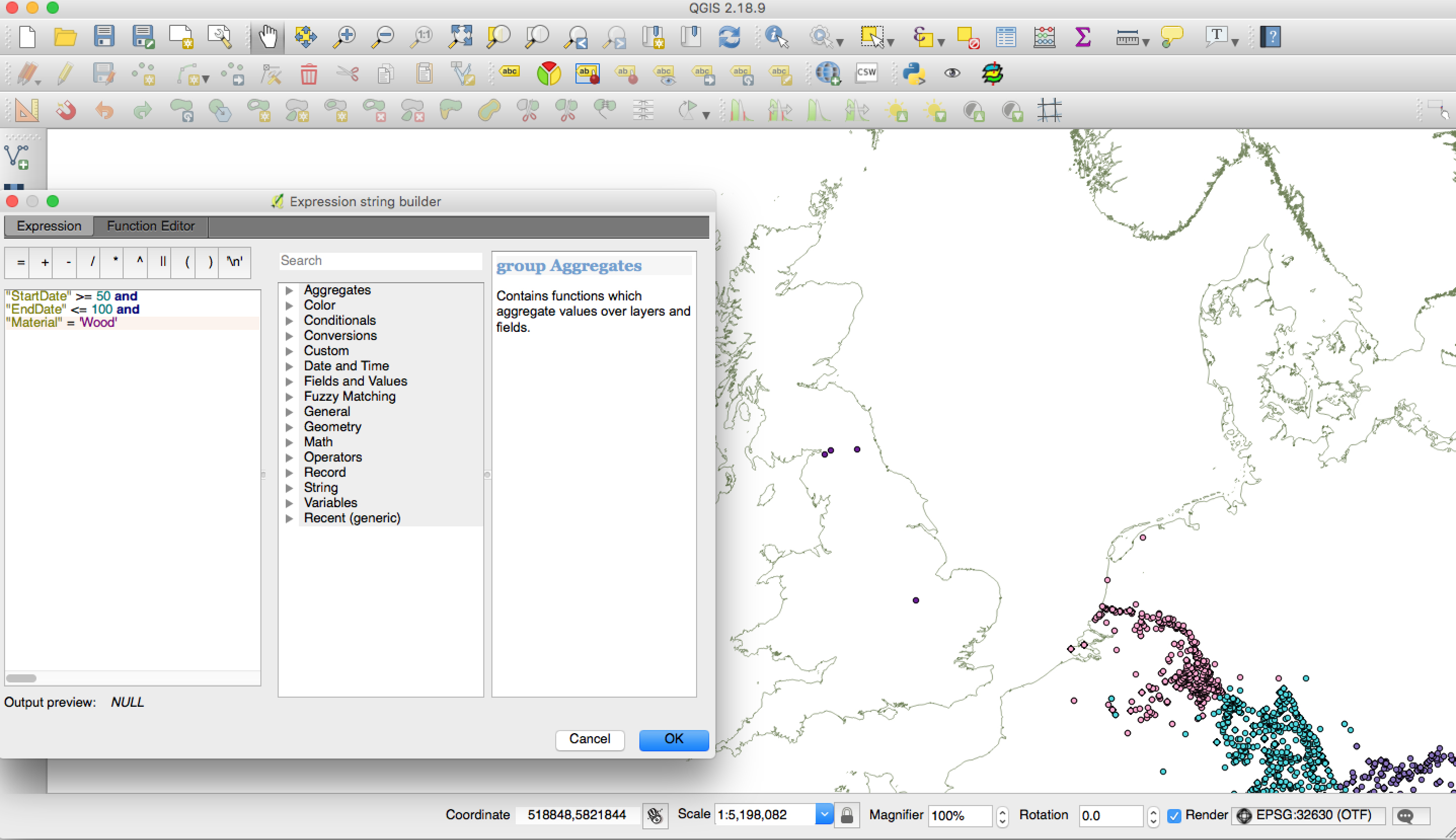
We do, however, already have a ‘dirty’ research version of the GIS, for use by the project team. We have been playing around with search queries, and have started to look for spatial patterns in the inscriptional record. As an example, here is a search which brought up inscriptions from Britain dated between AD 50–100 and written on wood. In addition, we have been visualising our inscription points against freely available GIS data from other projects (e.g. OxRep, PAS), in order to think about the social factors
which might have affected the uptake and use of Latin. For example, do we find more stone inscriptions the closer we go to quarries? How does the epigraphic habit change with the movement of the military? What does the distribution of writing equipment tell us about literacy and Latinization in the various provinces? The quality of the data available is necessarily different across provinces, but the GIS allows us to ask questions about Latinization at various scales across the whole project area.
Work on the project GIS is ongoing. The main priorities at the moment are the cleaning of the EAGLE data; the addition of the non-Classical language inscriptions, and the input of more contextual data alongside our inscriptions.