The Gaulish inscription from Saint-Germain-Sources-Seine (France) is ‘biscriptal’. The language is Gaulish, with a change of script from Latin to Greek for the Gaulish artist’s signature. Musée archéologique de Dijon https://riig.huma-num.fr/documents/CDO-02-01
One of the elements we needed to flag in the vast LatinNow epigraphic dataset were bilingual texts of all types, whether texts in two versions in different languages or texts in primarily one language but showing evidence of one or more others. I’ve been working on ancient bi- and multi-lingualism since I started my graduate work on Southern Gaul and since then I’ve collaborated with modern sociolinguists. The vast majority of the research on modern bilingualism has been based on oral evidence, though the relatively new field of linguistic landscapes has made steps to bring in writing. Since an established classification system for bilingualism in epigraphy was not available when I was writing my doctorate, I suspected one probably did not yet exist for digital epigraphy, Graeco-Roman or otherwise. Wide consultation during the opening phases of the LatinNow project confirmed my suspicions.
‘Partial bi-version bilingual text’, Latin and Punic, from Lepcis Magna (Libya) (IRT 321 and IPT 24a)
The messiness of the realities of spoken bilingualism and the creativity and range that one might see in written texts might seem to resist classification. Indeed for my thesis, I shrunk away from creating too elaborate a typology, simply producing what I needed for my immediate needs. But whilst there will always be ambiguous examples, edge-cases and epigraphic texts that resist categorization altogether, there are clearly recurrent features which make an attempt at a standardized and comprehensive typology of epigraphic bilingualism worthwhile, not least because we can then group similar types across time and space and link them to the research of modern sociolinguists who tend to have a lot more data and context to guide interpretations. It’s also handy for digital epigraphy to offer a scheme that researchers on different projects can start using as soon as possible, so that examples can be tagged and our datasets expanded.
The Velleron (France) stele. This can be tagged as Text with bilingual phenomena: code-switching and Text with biscriptal phenomena: transliteration since it is in Gaulish language with a code-switch into Latin at the end, VALETE, which is transliterated into Greek script. https://riig.huma-num.fr/documents/VAU-16-01
The categorization and vocabulary that I have produced draws on our work in the LatinNow project, inspired by the late Jim Adams. It works well for western epigraphic remains and has been vetted by several colleagues. I’m particularly grateful to James Clackson and Alessandro Palumbo who gave insightful and constructive feedback. I’m even grateful to the colleague who told me she eschewed such categorizing work, because that made me think harder about why it is so important.
The team over at the FAIR project are using the schema I have devised as a test case for what they would eventually like to do for all epigraphic vocabularies – establishing URIs for the categories (‘attribute values’) and using RDF so that interconnection of data will be possible long-term. Since in that forum it will be hard to have extensive explanations and caveats, I present the detail in a pdf below and encourage criticism via email: alex.mullen@nottingham.ac.uk. This is an ideal opportunity to create a useful, copious and standardized approach to encoding bilingualism in epigraphy, that works for the whole community.
LatinNow is an interdisciplinary project, which means that we take a holistic approach to epigraphy. We think it is essential to look beyond the text and consider the inscribed object along with it: without it, an inscription can lose not only its sense but also its visual and physical impact. We try to follow this approach when working on our epigraphic dataset as much as possible, but we have had to accept that it can sometimes conflict with the more traditional epigraphic categories that were established, often during the 19th century, with a focus on monumental and mostly lapidary inscriptions. Older epigraphic editions often make no mention of the inscribed monument at all, or only in a very vague manner; epigraphers only saw the texts as their remit, and since research at the time was focused on political and institutional history, lapidary inscriptions were considered to be of particular interest. One epigraphic category in particular has suffered from such pronounced priorities, that of inscribed instrumentum, or instrumentum domesticum, as it is often called – with significant consequences for Digital Epigraphy.
The term instrumentum requires some explanation. The Latin word first of all means ‘tool’, but it can be used as a collective term, a singular for plural, to describe ‘equipment’ more generally. Instrumentum domesticum can thus be understood to encompass all kinds of utensils, tools, and smaller objects that are used in a domestic environment. However, while in some languages, such as French, instrumentum can be used for small finds in general, including the uninscribed, it is mainly used as an epigraphic category in English, to describe stamps, graffiti and other texts found on small finds. To the epigrapher trained on monumental stone inscriptions, which is still how epigraphy is usually taught, the vast range of objects, materials, text types and execution techniques involved can be confusing at first: to understand them, some knowledge about the inscribed objects themselves is required, and small finds archaeology is itself a specialized skill.
The Corpus Inscriptionum Latinarum provided one of the earliest systematic approaches to inscribed small finds, by dedicating specific sections entitled ‘instrumentum’ or ‘instrumentumdomesticum’ to them (e.g. CIL I.2 1491–1499, CIL XII section XXIII), and then with CIL XV a whole volume (Rome). They contain inscriptions on portable objects such as bricks, tiles, vessels made of ceramic and glass, lamps, metal ingots, finger-rings, and various objects made of silver or bronze. Over time, however, the term has become more and more vague and its use more and more inclusive, with the most comprehensive approach perhaps being that of Roman Inscriptions in Britain vol. II: under the title ‘Instrumentum domesticum (personal belongings and the like)’ it also includes non-monumental inscriptions on non-portable support such as wall graffiti and mosaic inscriptions. Based on the fact that numerically the vast majority of inscriptions on small finds are related to production and commerce, attempts have been made to claim the term instrumentum solely for the epigraphy of production and economy, but in reality, makers’ marks, religious dedications, declarations of love and accounting notes have all found a home in the instrumentum category. It has become a catch-all for all the ‘small stuff’.
Because of its diverse nature, inscribed instrumentum is often neglected and under-published, in turn making it difficult for researchers to include this material in projects and studies as it often involves painstakingly searching e.g. AE and CIL. This neglect stands in stark contrast with the potential of inscribed small finds for numerous research questions, as demonstrated by the work made possible thanks to the herculean effort of recording and digitizing of stamps on Gaulish terra sigillata (https://rgzm.github.io/samian-lod/). We want to be able to study the distribution of the goods from a specific workshop, for example, or the production process in workshops of different sizes, or the social status of those involved in certain branches of production and commerce, which can be studied through onomastics. We might use this evidence to think about levels and types of literacy in different social contexts. Non-monumental inscriptions can give us a peek beyond the ostentatious and often ambitious sphere of stone inscriptions, which are frequently related to the higher echelons of society and have the distinctive purpose of displaying something to a wide audience or the public. Instrumentum allows us to see the same part of society expressing themselves in a more intimate way and environment, and even more often it tells us about those parts of society that are less likely to feature in stone inscriptions, such as those involved in production and trade, or those living in more rural areas. I’m currently working with Michel Feugère, French small finds expert, to think through some of these issues via the inscribed examples on his Artefacts database.
Inscribed small finds have received more attention over the past decades, amongst other things because of an increased interest in the material aspects of literacy, and efforts have been made to pull them into the spotlight, e.g. through the publication of the Instrumenta inscripta volumes. But with Epigraphy moving on from a focus on stone inscriptions to including more diverse categories, and from producing print corpora to putting digital tools to use, the old category of instrumentum has produced its own set of challenges, and projects striving to make it more accessible online are taking them on, including our own.
A particular challenge for Digital Epigraphy is the categorization of inscriptions in a way that works across different projects and datasets, and bringing together existing datasets, and the FAIR Epigraphy project led by Marietta Horster and Jonathan Prag and the ongoing efforts of epigraphy.info are tackling exactly this problem. But as far as instrumentum is concerned, the sheer number of diverse object- and text-types involved means that the researchers populating the existing databases often lacked the terminology (or the inclination) to take care over its classification. Accordingly, instrumentum can be found as a category of objects in many databases, rendering it impossible to, for example, search for stamped plates or inscribed spoons, and leaving us with a huge job to do.
In a print edition it can be difficult to do justice to both the archaeological and textual nature of inscribed instrumentum – a decision has to be made how to structure the publication, according to object type or text type, for example, and for each inscription, a decision has to be made as to which category it belongs to. Digital editions are not bound to such linear structure and there is theoretically no limit to what can be encoded, for example in EpiDoc. But we need to put in the effort and avoid catch-all categories such as instrumentum. Digital Epigraphy means that we have tools to manage much more copious and detailed information than is the case with the index of a print edition, and that we can combine the existing criteria in innumerable ways when searching databases and exporting datasets from them. We should make use of this opportunity.
In March 2020, Simona, Pieter and I met in London for one of our team meetings, with Alex joining us on video call because she had a baby and there was talk of a new virus. The three of us went for dinner and drinks at the end of the day, and we vividly remember the moment we said goodbye because we laughed about our silly ‘COVID handshakes’. Little did we know… Since then I have bumped into Simona in the courtyard of the Senate House, each clutching to our laptops, during a fire alarm that forced us to go for a coffee and a catch-up. Alex and I also met Scott to shoot our conversation about Roman writing equipment, and I have seen Pieter on screen for coffees, team meetings and study sessions. But in March 2020 we never thought it would be so long before we were, as an extended team, all in the same place.
Now we are adapting to a less restricted lifestyle and this month marked a very special occasion indeed, as we all met up together in Oxford for the first time in years, including extended team members that flew in from Spain, the Netherlands and the US.
Group selfie at a really big breakfast table at All Souls
Having updated each other about the numerous LatinNow babies, and grand-babies, we all immediately realised how helpful it is to be working together in the same room, to have time to mull over things and dip in and out of conversations over the course of hours and days. The main reason for the meeting was the joint volume we are currently working on, with each of us writing chapters on Latinization, local languages and literacies in our respective geographical areas of research. It has been really useful to discuss our draft chapters to identify common themes, bounce problems off each other and make sure we cover important aspects without overlapping too much – linguistic developments did not stick to Roman province boundaries and historic periods, after all! This was particularly important for Pieter, Noemi, Maria José and Javier, who are all writing about the Iberian Peninsula, an area with multiple pre-Roman local epigraphies.
Pieter, Noemí, Javier and MJ data wrangling at the CSAD
Getting together also had the advantage that we could all sit around a big screen and have a play with our data. We are also currently working on a WebGIS that will be made publicly accessible later this year. It will allow users to visualise our epigraphic dataset against the backdrop of a map and to add other features such as roads, production centres, settlements and province boundaries, to contextualise it with factors that played a role in the spread of Latin. It will also be possible to filter our epigraphic dataset and for example display inscriptions on stone, non-Latin inscriptions or only funerary inscriptions together with these different factors. Scott, Simona and Pieter in particular have worked hard on our data and we have refined it to the point where it might even allow us to rethink our knowledge about Latin stone inscriptions more generally, but that is a topic for another blog… All of us are making use of the epigraphic dataset for our chapters, so it was really helpful to display on a large screen what we have been turning around in our heads, to play with different sets and to identify data we can improve or would like to add: why are there several lapidary inscriptions in Brittany? Isn’t that a really anepigraphic zone? Zoom in, add the layer for Roman roads, boom: they’re all milestones! Can we add the locations of mints/mining? As it turns out, coin legends are amongst the earliest evidence for Latin literacy in many of our areas. Which of the existing datasets has the most accurate information on settlements? And what are those dots in the ocean? Careful not to dismiss them as dump sites for inscriptions without coordinates (we’ve been very careful to consider that throughout the data cleaning process), Porcupine Bank is real! Discussion often started at the breakfast table and continued all day and into the evening as we wanted to make the most of our time together. It was hard to get a break in! (Shout out to the staff at a certain Pizza restaurant that let three of us hold down a table for eight for almost an hour whilst half the group couldn’t tear themselves away from the mapping! We did order olives, though…)
Scott and Alex cramming in more work just before the British Epigraphy Society meeting began
After three days of intense teamwork, the week ended with the Spring colloquium of the British Epigraphy Society, which was held in memory of Jim Adams, one of our project Special Advisors, at the CSAD. The speakers (including our own Alex and MJ) took us on a tour of exciting projects that were inspired by Adams’ ground-breaking work, from Spain and the northwestern Roman provinces to Illinois, Egypt and Pompeii, exploring regional and social linguistic diversity, translation techniques and even the vocabulary of bodily functions. It was wonderful to see how Adams’ work is being developed further and taken in new directions; his legacy truly lives on, and LatinNow is proof of it.
The last few days we’ve been working hard again on our epigraphic database. We have just released a video which describes a little how we will use this in combination with our other datasets to try to answer some big historical questions about life and languages in the Roman west. It’s a talk Pieter (in the Netherlands) and I (in the UK) gave jointly on a Friday night for the Digital Humanities centre at San Diego State University. We had a great host – David Wallace-Hare (the David I occasionally mention in the talk!) – to whom our thanks for the invitation. It was nice to be asked to talk specifically about the DH side of our project.
In our last blog, we explained the nature of our epigraphic dataset and some of our tasks over the past couple of years. We are now very close to pressing the button to initiate ‘The Great Merge’. Up until this point we have been working with 181,000+ different EpiDoc records mostly from EAGLE which are derived from a number of digital epigraphic sources. Over the last couple of years we have identified, by machine and by hand, many thousands of duplicate records (in addition to the numerous duplicates already found by EAGLE). Now we will merge these records to make one set of records (c. 135,000) for each text-bearing object and will assign them LatinNow URIs. All the original data will, of course, also be kept. And everything will be open access.
Merging records might sound straightforward but what goes into the single merged record is complicated and requires even more complicated coding (the latter our wonderful Technical Director’s specialty thankfully!). Everything is fine if the attributes in each record match or one provides metadata that the other doesn’t. The issue is when the values for the same attribute in the duplicate records don’t match. The first pass at the merge coding turned up a scarily high number of non-matching attributes, over 24,000, even after our attempts at harmonizing the vocabularies and cleaning of the dataset. Luckily a good chunk of these are solved by adding rules about hierarchy (‘stone’ and ‘stone: limestone’ are not conflictual) and telling the machine how to cope with the same attributes which been assigned differing levels of confidence. Many of the non-identical attributes are also complementary – so we can tell the code to keep both of them when merging the records. But there, as always, remains a set of ‘problematic cases’. It is unlikely, for example, that the same inscription is simultaneously ‘stone’ and ‘ceramic’ (perhaps a researcher in one of the source epigraphic databases has assumed votive texts with VSLM will be on stone for example), and inscriptions are rarely both a milestone text and an epitaph. We have had to find clever ways to deal with these but many must be checked by hand.
One example may serve as an indicator of some of the knotty issues we face. As ancient historians we are interested in mapping the lapidary epigraphic habit so it is important that we have a reliable set of georeferenced data points of stone inscriptions. A few stone inscriptions have the attribute ‘material: rock’ in the database. Of course stone is also rock, but epigraphers do normally want to make a distinction. Worked rock – what we call stone – made into an object that is then inscribed (e.g. a tombstone or an altar) is different from rock in a cave or mountainside that is carved or scratched into directly. There are interesting links to make between the two formats, but we want to be able to categorize them separately and not subsume the rock inscriptions into the much larger lapidary set. We can of course keep rock within the series of attributes for the material of lapidary texts, for example having rock, stone and limestone in a descending hierarchy.
View of the Lances de Malissard (photo: Patrice78500, CC-BY-SA-3.0)
One of our fun tasks this past week was trying to ensure the rock and stone inscriptions were not lumped together. Pieter took on the Iberian Peninsula, Anna the Germanies and I Gaul and Britain. This led me to rediscover some really interesting rock texts, including the slightly unusual text on a rock face of the crête de Malissard, which reads hoc usque Aveorum, which can be translated roughly as ‘this is the border of the territory of the Avei (?)’ and shows the double I for E which is much more common in handwritten texts using the stylus than in rock or stone-carved texts. Who the Avei (?) might be is unclear. It’s an intriguing inscription to which I’d like to return, and perhaps even try to visit one day when travel is permitted.
Rock-hewn inscription on the crête de Malissard (photo: Yoan Mollard, CC-BY-SA-4.0)
Next up for our post-‘Great-Merge’ database is to decide exactly how we can best make our data accessible for the general public and the academic community.
By Simona Stoyanova, Scott Vanderbilt and Alex Mullen
We play with a lot of data in the LatinNow project and we thought we’d tell you a little about our biggest dataset: the 180,000 record strong epigraphic database.
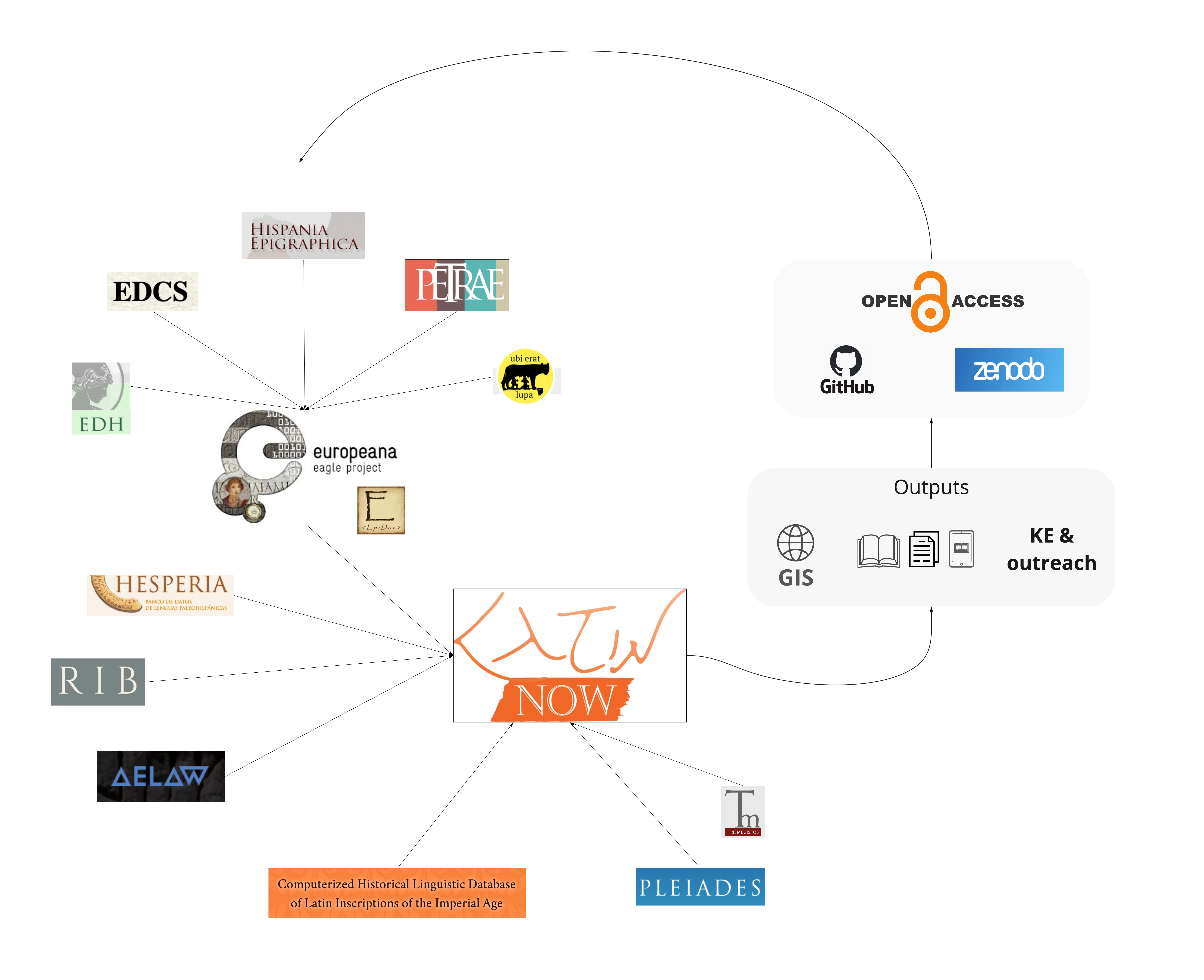
Considering the large geographical and temporal scope of LatinNow, we asked the EAGLE-Europeana network to share their epigraphic data from the north-western provinces. They kindly agreed and that was the start of our core dataset. That meant that we had EDH, EDCS, Hispania Epigraphica, Ubi Erat Lupa and PETRAE, amongst others, all in EpiDoc, while data from RIB is being added directly by Scott. Of course, the different focus and approach of each of these corpora mean that the granularity of encoding is different – e.g. some projects annotate evidence for dating or very detailed provenance information while others are more interested in the text and provide minimal metadata. However, the shared use of the EpiDoc standard and EAGLE’s efforts enabled us to leverage all available metadata and to query records on a scale otherwise impossible.
We gradually started adding our own corpora into the mix – e.g. Gaulish (Gallo-Greek and Gallo-Latin), Raetic and Noric, as well as the spindle whorl collection discussed here. Using the same attributes and vocabularies allows us to query and compare features of these inscriptions alongside those coming from EAGLE and RIB. Simona also worked with Francesca and Alex on picking a set of socio-linguistic attributes, starting from the massive list in the Computerized Historical Linguistic Database of the Latin Inscriptions of the Imperial Age and building on Francesca’s and Alex’s linguistic research on specific regions. After much debate we decided on half-a-dozen most representative and relevant for our provinces (particularly those with relevance for language contact). Mapping these with our more precise coordinates gives us a clearer picture of socio-linguistic processes across the western part of the empire.
Representation of data flows to and from the LatinNow project (Simona Stoyanova)
Data can be a messy business and has to be curated and analysed with care and understanding of the principles followed in its collection. Differences in encoding, as mentioned above, come from project-specific needs, while differences in, say, bibliographic reference style, may come from national practices, even personal preferences. Another issue can be the files’ date of publication. We noticed some duplication of records between our dataset and the current EDH, which turned out to be a case of EDH having updated those records post-2015 – the date of the EAGLE data transferred to us. Further complications arose from the different approach towards fragmentary texts/objects. While Trismegistos catalogues all parts of a fragment under one identifier, other data providers treat each fragment as a separate item with its own identifier. Each of these issues, and numerous others, had to be addressed with a combination of epigraphic, publishing, encoding and data science experience. Reconciling varying approaches to the recording of our material is no easy task and is not a trivial task.
We, especially Scott and Pieter, worked hard on the improvement of geospatial coordinates, since mapping is a key tool in our research. This involved pouring over publications in an attempt to figure out how to pin down ‘the south-west corner of Don Pedro’s farm’ and trying to work out why different projects had recorded sometimes radically different co-ordinates. It was always important to work out whether ‘dump sites’ had been deployed by projects, i.e. a consistently chosen central location used to place inscriptions whose provenance was not known e.g. beyond a province.
Messing around with mapping, Latin inscriptions and the road network (Pieter Houten)
We also spent a lot of time adding to and harmonizing attributes. A starting point for our metadata consolidation was the EAGLE vocabularies for material, object type and text type. The importance of EAGLE’s attempt at reconciling complex terminology in multiple languages from multiple projects cannot be overstated. It has made projects like ours possible and has encouraged the epigraphic community to work with more concertation on the digital future of our field. Currently, there is an effort from both the epigraphy.info and the Linked Pasts community to review and streamline the vocabularies, and build more robust Linked Open Data mechanisms around them. While we wait for this work to be completed, we spent hours debating issues such as: what is a Tafel vs table vs plaque vs tablet vs plate; do we actually need to leverage them with one or two terms, or can we keep them all and still perform meaningful searches and analyses?
But without a doubt the most time-consuming task was deduplication. Projects at the time of the download from EAGLE did not consistently link up their data – e.g. with a Trismegistos ID or similar. As a result, with downloads from multiple different digital epigraphic projects, some of the same objects had as many as half a dozen records. Finding them is easy if they share identifiers, but the majority were not straightforward to find, requiring bibliographical/text comparisons, for example. And ultimately, for a frustratingly large number, time-consuming checking of original publications. Once we have a fully deduplicated dataset, Scott will set in motion ‘The Great Merge’, which will allow the metadata from multiple projects to show under one new merged record, making one set of very rich records for our provinces.
Our metadata efforts are now bearing fruit beyond our own convenience. We are collaborating, for example, with the Michel Feugère at the CNRS Lyon, where he and his team are working on a corpus of inscribed small finds drawn from his Artefacts website. Our taxonomy has been consulted by them, to ensure consistency and compatibility between our data sets.
All of our research outputs will be open access and we follow the FAIR principles of data management for our digital assets. Our final results will be available in Zenodo, GitHub, and as many other repositories as we can find. We are in conversation with our colleagues to work out how best to feed back to them our additions to the data they provided. And, importantly, we will follow the best practice set out by the epigraphic community on standardization and Linked Open Data.
We thank all those projects who have shared data with us and look forward to our linked data future!
The LatinNow summer started with a training session for the Faculty of Arts at the University of Nottingham and our team on Digital techniques and resources for textual research. Led by Dr Gabriel Bodard (Institute for Classical Studies, London) and me, the DigiText workshop introduced our colleagues to four major digital approaches to humanities research: digital philology, text encoding, linked open data and linguistic annotation. The topics we covered included introduction to online resources, imaging techniques for cultural heritage, methods in digital palaeography, EpiDoc XML markup, LOD annotation, treebanking and translation alignment. While most of our examples were taken from the ancient Mediterranean, the principles and practices applied to all disciplines and cultures represented in the audience – from Scandinavian studies to modern languages translation studies. Our colleagues enjoyed a good amount of practice, starting with marking up modern gravestones in EpiDoc (the more errors and erasures the better), annotating and disambiguating place names in Recogito and aligning translations in Ugarit. Our aim was to showcase these major topics and what progress has been made in digital classics, as well as to highlight the applicability of these approaches and methodologies to virtually all textual research. We had fruitful discussions and quite a few ideas for future collaboration, both national and international – watch this space!
Dr Kathryn Piquette setting up the RTI highlight kit
Our second trip to Nottingham’s leafy University Park campus was for a training session in Reflectance Transformation Imaging (RTI), led by the fabulous Dr Kathryn Piquette. We were joined by a couple of colleagues all the way from Vindolanda who pulled all the stops with their multispectral filters. In two days we learnt how to put up and dismantle the RTI highlight setup, how not to drop a £2000 camera on a museum object, how to use a transmitter and how to hold one’s hand steady at 60°, 45°, 20° and 15° with no wrist tilting. The training covered the theory and physics behind RTI, followed by lots of practice. On the second day we processed the images we had taken the day before and produced our finished RTI images. The fortuitous incident of a foot just slightly nudging the board holding the object being imaged during one session showcased how/what things could go wrong, what to keep an eye out for and how to attempt fixes. We discussed various image-enhancing techniques and tools, tried one on a newly-imaged tablet from Roman Vindolanda and confirmed the reading of a stamp on a terra sigillata mould sherd from the University of Nottingham Museum collection. It was a whirlwind of a training, we learnt a great deal and are massively grateful to Kathryn!
A sherd of a mould from the University of Nottingham Museum collection being RTI-ed. It turns out that LEGO is ideal for holding the spheres!
From 8th-12th October, the Centre for the Study of Ancient Document in Oxford (HQ of the LatinNow Project) played host to two Year 11 students from the Cherwell School, with us as part of their Work Experience placements. In this guest blog, Charlotte W and Finlay HC dish the dirt on what it’s really like to work in the LatinNow office…
Charlotte writes…
“I didn’t really know what to expect from a week’s work experience at the Centre for the Study of Ancient Documents. As a fifteen-year-old, you hear many terrifying rumours of what life was like before the internet. What I definitely didn’t expect was to be asked to help contribute to LatinNow, a huge EU-funded project investigating the Latinization of the north-western Roman provinces, or to help document original artefacts from Nottingham University Museum for the LatinNow exhibition around Europe, including over 2000 year old coins and pottery sherds!
It was amazing to see these relics from our ancient past up-close and to begin to explore some of the stories they held. Dr Francesca Cotugno was kind enough to explain one of these objects, a replica of the tombstone of a Marcus Caelius, and I was very surprised to learn what a gruesome story it unlocked.
The story goes (and I hope I get this right…) that a German hostage of the Romans named Arminius managed to deceive everyone that he was loyal to the Romans. He gained Varus’s trust, a man highly respected by the Roman senate, then deliberately led him and the 3 Roman legions he commanded into a trap where they were slaughtered mercilessly by Germanic tribes. When the emperor Augustus found out about what happened he was so distraught, as Rome had never suffered a defeat like this ever before, he banged his head the wall shouting “Give me back my legions!”. Arminius was then killed by his own Germanic people as they decided the act he committed went too far and was too ruthless.
Tombstone of Varus, who died in AD 9 at the Battle of Teutoburg Forest in Germania.
This tombstone to Marcus Caelius is unusual as it explicitly says that he died in the Varian war. We don’t know much about his role in the war, but we know from his representation that he was a decorated soldier who must have been relatively wealthy as he is flanked by his freedmen.
I also, in the documenting process, came in contact (with gloves!) with several replicas of iron age coins. In the pictures we took, you can’t see exactly how small the coins were but they were tiny, smaller than a penny. And they were so intricately embossed.
Coinage was introduced to Britain during the Iron age and inscribed coins . Earlier coins mostly just had symbolic animals on them so therefore if there appeared to be writing you could tell it was from a later time. There were also much bigger and chunkier coins from the Roman period, (these were originals so I was constantly holding my breath when getting them out of the bags) which had the name and carving of the Roman Emperors on them. I hope in the pictures you can see how ornate they all are and can get a sense of how incredible it was see things that have been used by our ancient ancestors.
So coming out the other end of this week, I’m relieved to report that Classics is not just some musty dusty academia for elderly scholars, I’ve found it to be entirely different. It’s exciting and very interesting for curious minds, and even though at the beginning of the week I didn’t have a clue what I was going into, I have really enjoyed myself. So thank you LatinNow!
Finlay writes:
“On Monday the 8th of October I arrived at the Centre for the Study of Ancient Documents for work experience. In large part this involved looking at ancient writing equipment for the LatinNow Project. As part of this project to study the Latinization of the North-Western Roman Empire team is using ancient writing equipment as a means of demonstrating how Latin spread throughout Gaul (present day France and Belgium), the Iberian peninsula (present day Spain and Portugal), the Germanias and Britannia (present day Germany and Britain).
For the most part, my work involved summarising the data from British archaeological sites where Roman writing equipment had been found. The hope was to show to what extent Latin had caught on in Britain and compare it the rest of Roman Europe, and so better understand why different local cultures adapted to Roman rule differently. For example, in many of the British archaeological sites ancient Roman styli were found. A stylus, as I found out over the course of the week, was a sharp metal object used to scratch letters on a wooden tablet covered in beeswax. Some of the other artefacts I was looking for were inkwells, seal boxes (used to protect the seals that were used on papers or bags) and wax spatulas (these were used to scrape the wax back into place on a tablet for reuse). As these were methods of writing the Romans used and introduced to Europe, the amount of these objects found in an area could indicate literacy, as well as how common Roman culture was there. The notes and locations took the form of a grand database that I had the opportunity to help fill out.
Working with Charlotte, a fellow student from Cherwell school, we also had the chance to help in curating part of the touring exhibition that is part of the project. We were given a selection of ancient artefacts to measure, weigh and photograph and record in a table. Although we had to wear glove, handling the ancient pottery and coins, with my own hands was an especially interesting and unique experience. The coins in particular were extraordinary as you could see the dents and scratches of a lifetime’s use, without having to look through a glass display case. One coin was from the rule of Marcus Aurelius and you could see the wear and tear from its use throughout his 19 years as Emperor.
Four Roman coins in the LatinNow Touring Exhibition, on loan from the University of Nottingham
The last part of my work on the LatinNow project involved looking at a database of archaeological sites in the Iberian Peninsula under the guidance of Dr Noemi Moncunill, and finding the coordinates of the sites to add to the table. For instance, Torre Alta in Cadiz was one of the sites and the coordinates were 36.52 by -6.149. The end goal of this part of the project was to use the coordinates to create a geomap of Roman writing equipment to visually demonstrate how Latin spread throughout the area. Comparing this to data found in Britain will demonstrate how Latinization uniquely affected native cultures and why people took Latin up – such as status, economic success, citizenship, or literacy.”
The LatinNow and CSAD teams are very grateful to both Charlotte and Finlay for all their hard work during their time with us, and for agreeing to be our guest bloggers this month. Thanks, both!
Later this month, on 26th October, we’re appearing in the Ashmolean Museum’s LiveFriday event ‘Spellbound’. Come and find us in the Reading and Writing Gallery to learn how to put a Roman curse on your enemies. More on this in next month’s blog!
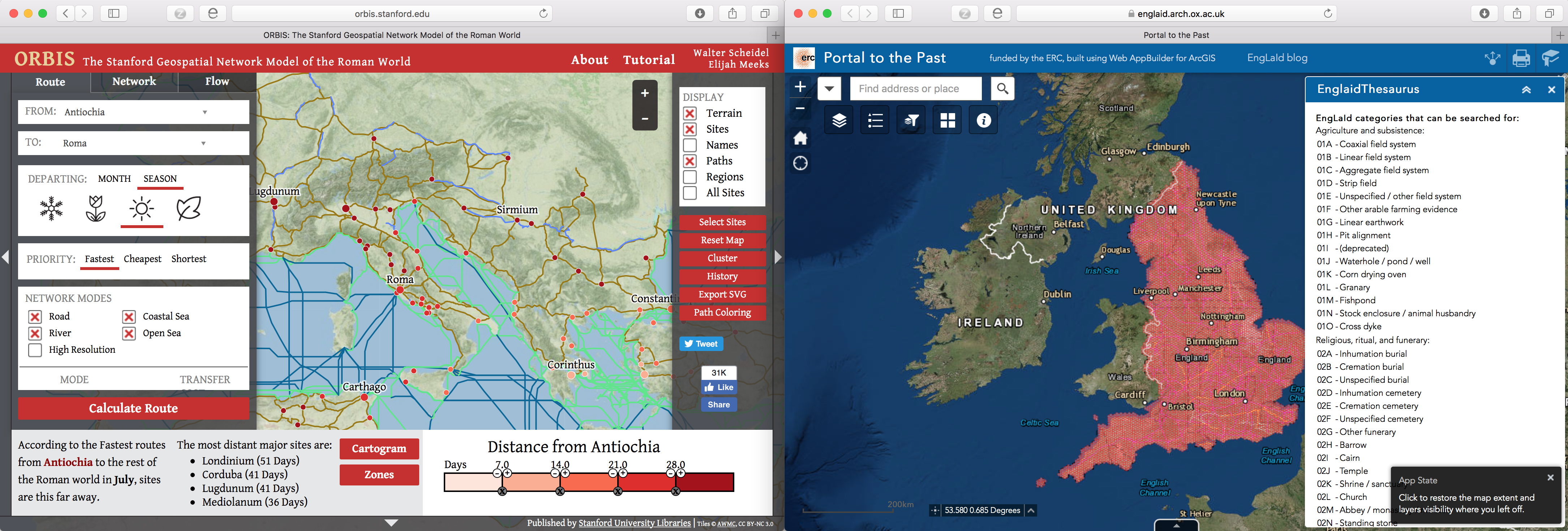
One of the planned outputs for LatinNow is a publicly accessible GIS. This will be an easily navigable web-based interface (similar to tools produced by ORBIS or EngLaId), which will display, amongst other things, inscriptions of the north-western Roman provinces as points on a map. Users will be able to search for inscriptions, filtering the data by e.g. location, date, and inscribed material; and then be able to display the text of the target inscription.
Public-facing GIS tools from ORBIS and EngLaId
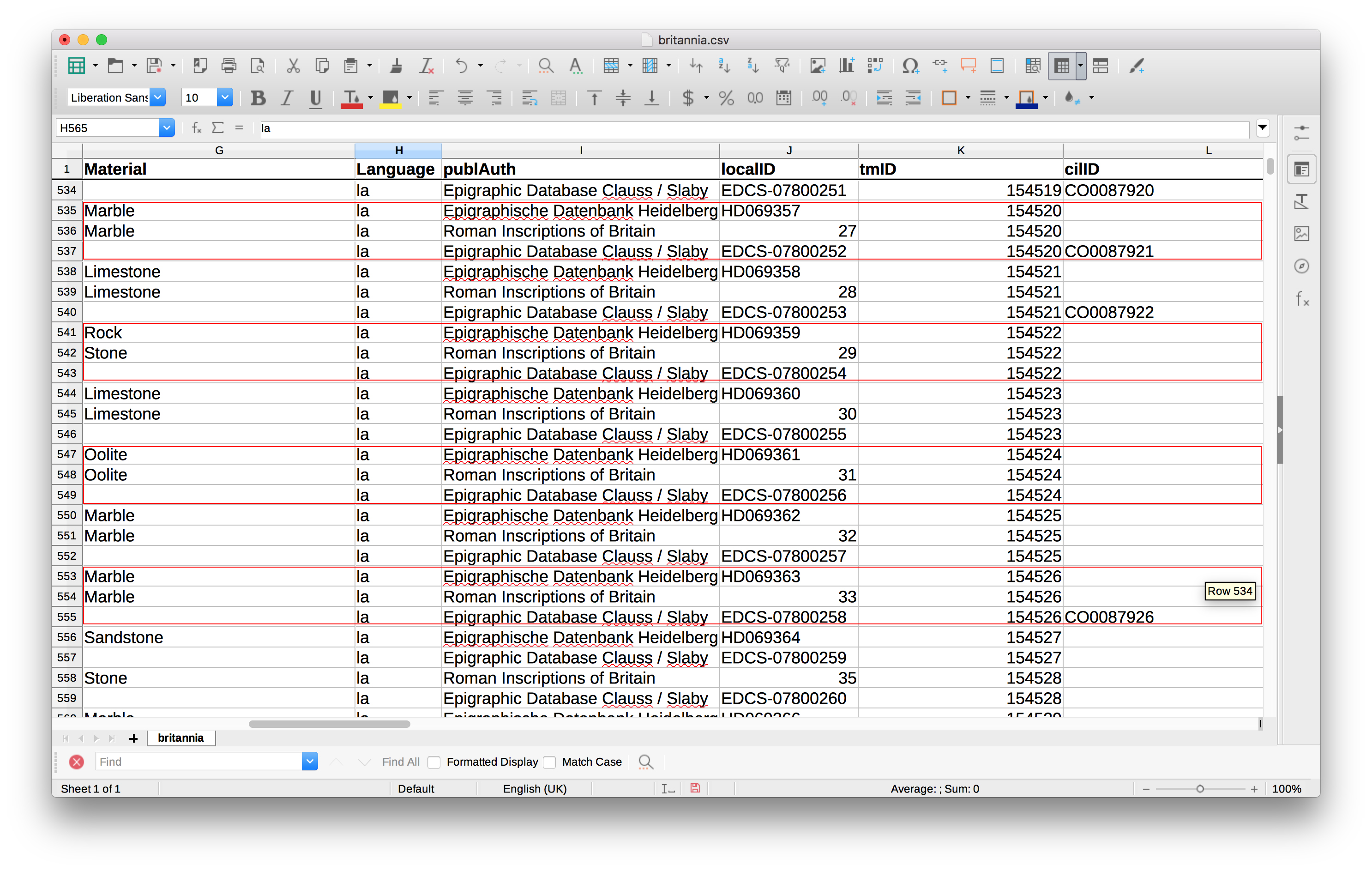
The data for the Latin and Greek inscriptions in this GIS comes from EAGLE, and comprises over 180,000 inscriptions marked up (largely through an automated process) with EpiDoc. With the help of our European Special Advisor Pietro Liuzzo, we obtained a collection of all the EAGLE files relevant to our provinces of study — i.e. the collection of ‘Classical’ language inscriptions which we can use in our GIS. However, it is not simply a case of dumping these files straight into a GIS: the collection contains multiple appearances of the same inscription in different Epigraphic corpora (e.g.Epigraphic Database Clauss Slaby; Epigraphische Datenbank Heidelberg; Roman Inscriptions of Britain), or even different editions/readings of the same text from the same corpus. We have also identified some problems with the automatic EpiDoc’ing process. For example, some of the files were EpiDoc’ed without geographic co-ordinates — essential references for displaying the data geospatially — and much work is therefore needed to make the data ‘GIS’ ready, either by manually adding in co-ordinates or linking the data up with Pleiades (where possible). The GIS team is currently dedicating most of its time to the cleaning and processing of the material in this way.
Multiple entries for the same inscription from different Epigraphic corpora. Entries with the same ‘tmID’ refer to the same inscription.
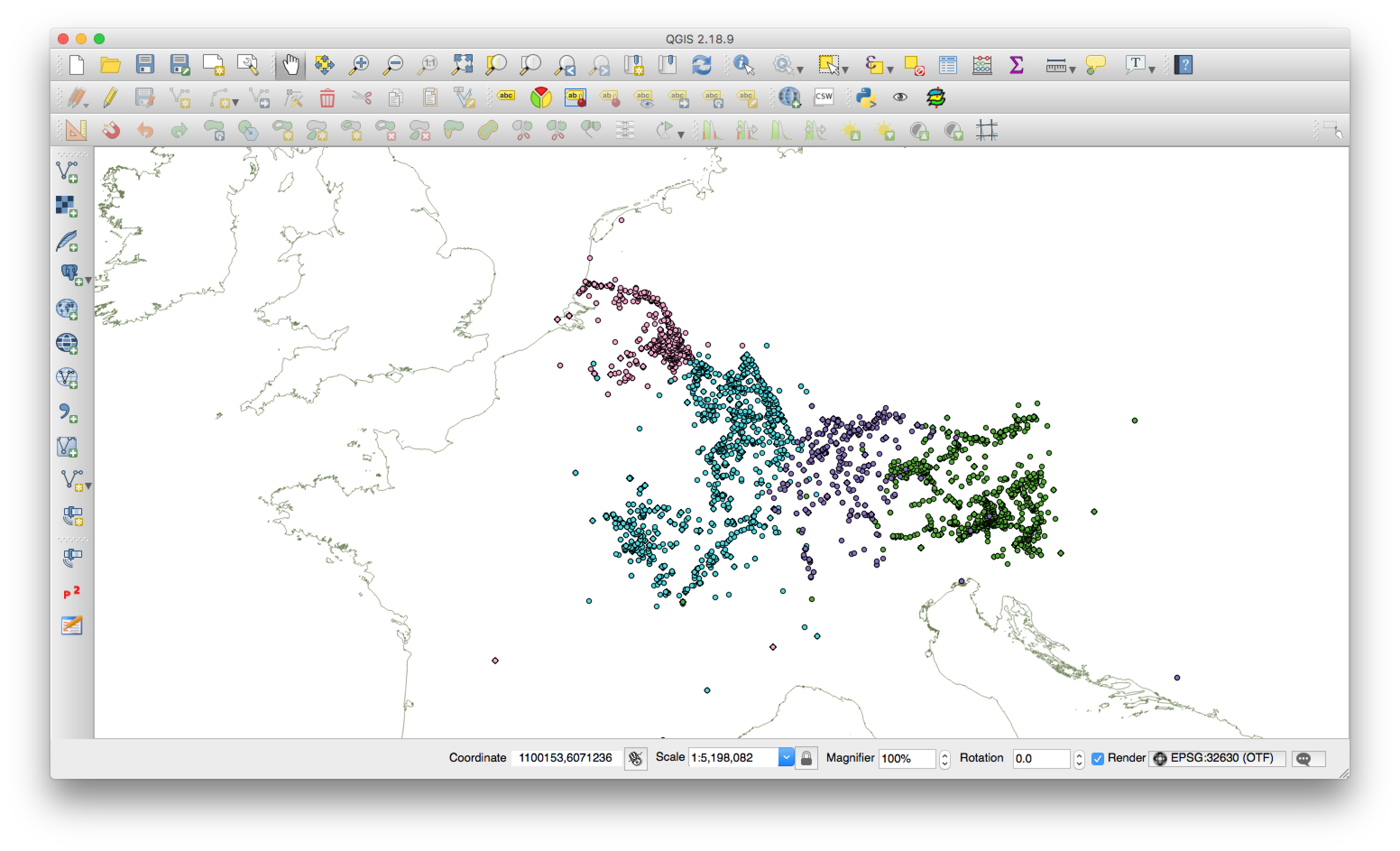
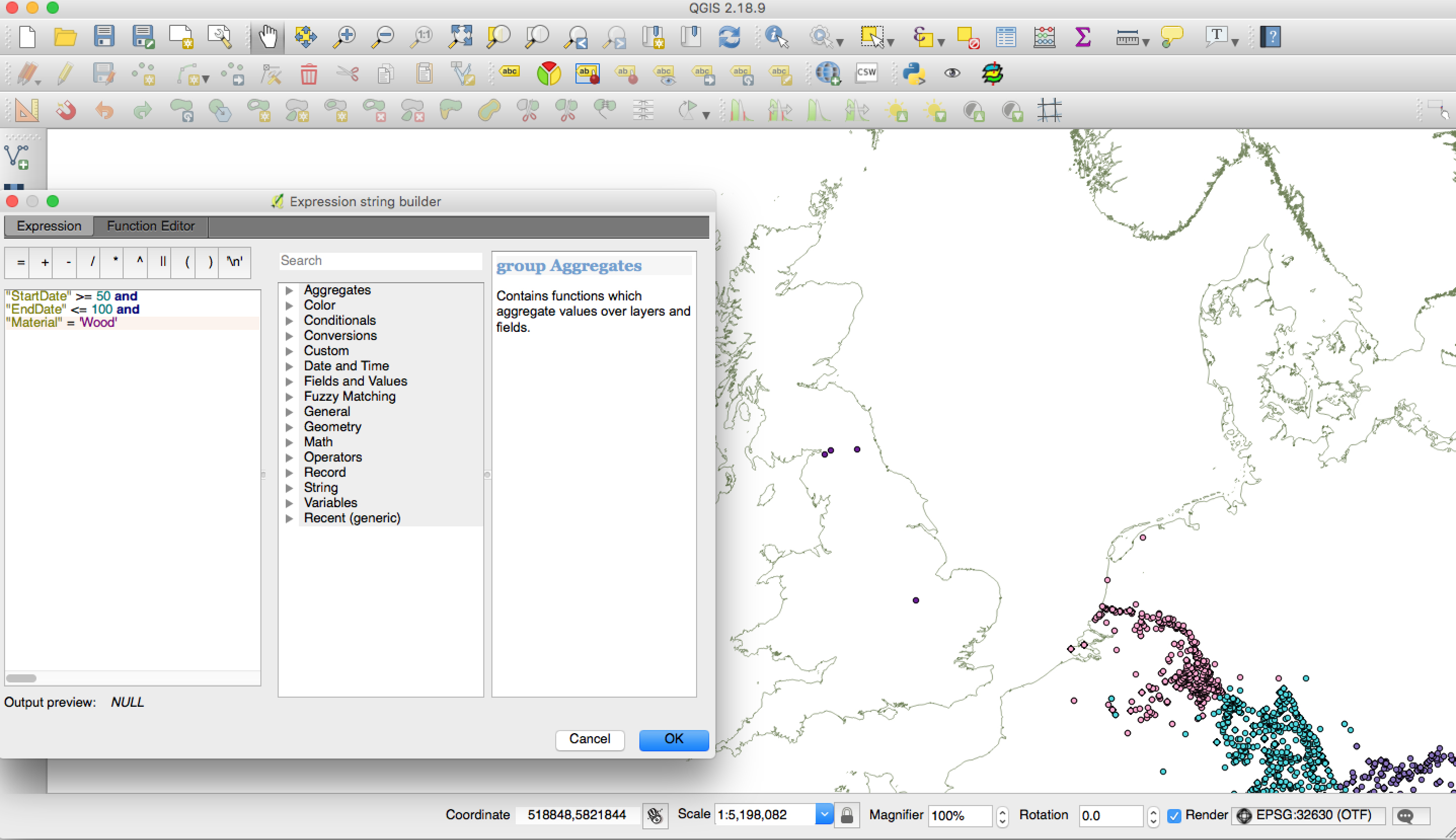
We do, however, already have a ‘dirty’ research version of the GIS, for use by the project team. We have been playing around with search queries, and have started to look for spatial patterns in the inscriptional record. As an example, here is a search which brought up inscriptions from Britain dated between AD 50–100 and written on wood. In addition, we have been visualising our inscription points against freely available GIS data from other projects (e.g.OxRep, PAS), in order to think about the social factors
Screenshot of the ‘dirty’ data, from the Germanies, Noricum, and Raetia.
which might have affected the uptake and use of Latin. For example, do we find more stone inscriptions the closer we go to quarries? How does the epigraphic habit change with the movement of the military? What does the distribution of writing equipment tell us about literacy and Latinization in the various provinces? The quality of the data available is necessarily different across provinces, but the GIS allows us to ask questions about Latinization at various scales across the whole project area.
Example query run on the inscriptions of Britannia. Here, inscriptions dated AD 50–100 and written on wood (missing, for example, the Bloomberg tablets, which have not yet been published online).
Work on the project GIS is ongoing. The main priorities at the moment are the cleaning of the EAGLE data; the addition of the non-Classical language inscriptions, and the input of more contextual data alongside our inscriptions.














 The LatinNow summer started with a training session for the Faculty of Arts at the University of Nottingham and our team on Digital techniques and resources for textual research. Led by Dr Gabriel Bodard (Institute for Classical Studies, London) and me, the DigiText workshop introduced our colleagues to four major digital approaches to humanities research: digital philology, text encoding, linked open data and linguistic annotation. The topics we covered included introduction to online resources, imaging techniques for cultural heritage, methods in digital palaeography, EpiDoc XML markup, LOD annotation, treebanking and translation alignment. While most of our examples were taken from the ancient Mediterranean, the principles and practices applied to all disciplines and cultures represented in the audience – from Scandinavian studies to modern languages translation studies. Our colleagues enjoyed a good amount of practice, starting with marking up modern gravestones in EpiDoc (the more errors and erasures the better), annotating and disambiguating place names in Recogito and aligning translations in Ugarit. Our aim was to showcase these major topics and what progress has been made in digital classics, as well as to highlight the applicability of these approaches and methodologies to virtually all textual research. We had fruitful discussions and quite a few ideas for future collaboration, both national and international – watch this space!
The LatinNow summer started with a training session for the Faculty of Arts at the University of Nottingham and our team on Digital techniques and resources for textual research. Led by Dr Gabriel Bodard (Institute for Classical Studies, London) and me, the DigiText workshop introduced our colleagues to four major digital approaches to humanities research: digital philology, text encoding, linked open data and linguistic annotation. The topics we covered included introduction to online resources, imaging techniques for cultural heritage, methods in digital palaeography, EpiDoc XML markup, LOD annotation, treebanking and translation alignment. While most of our examples were taken from the ancient Mediterranean, the principles and practices applied to all disciplines and cultures represented in the audience – from Scandinavian studies to modern languages translation studies. Our colleagues enjoyed a good amount of practice, starting with marking up modern gravestones in EpiDoc (the more errors and erasures the better), annotating and disambiguating place names in Recogito and aligning translations in Ugarit. Our aim was to showcase these major topics and what progress has been made in digital classics, as well as to highlight the applicability of these approaches and methodologies to virtually all textual research. We had fruitful discussions and quite a few ideas for future collaboration, both national and international – watch this space!