By Simona Stoyanova, Scott Vanderbilt and Alex Mullen
We play with a lot of data in the LatinNow project and we thought we’d tell you a little about our biggest dataset: the 180,000 record strong epigraphic database.
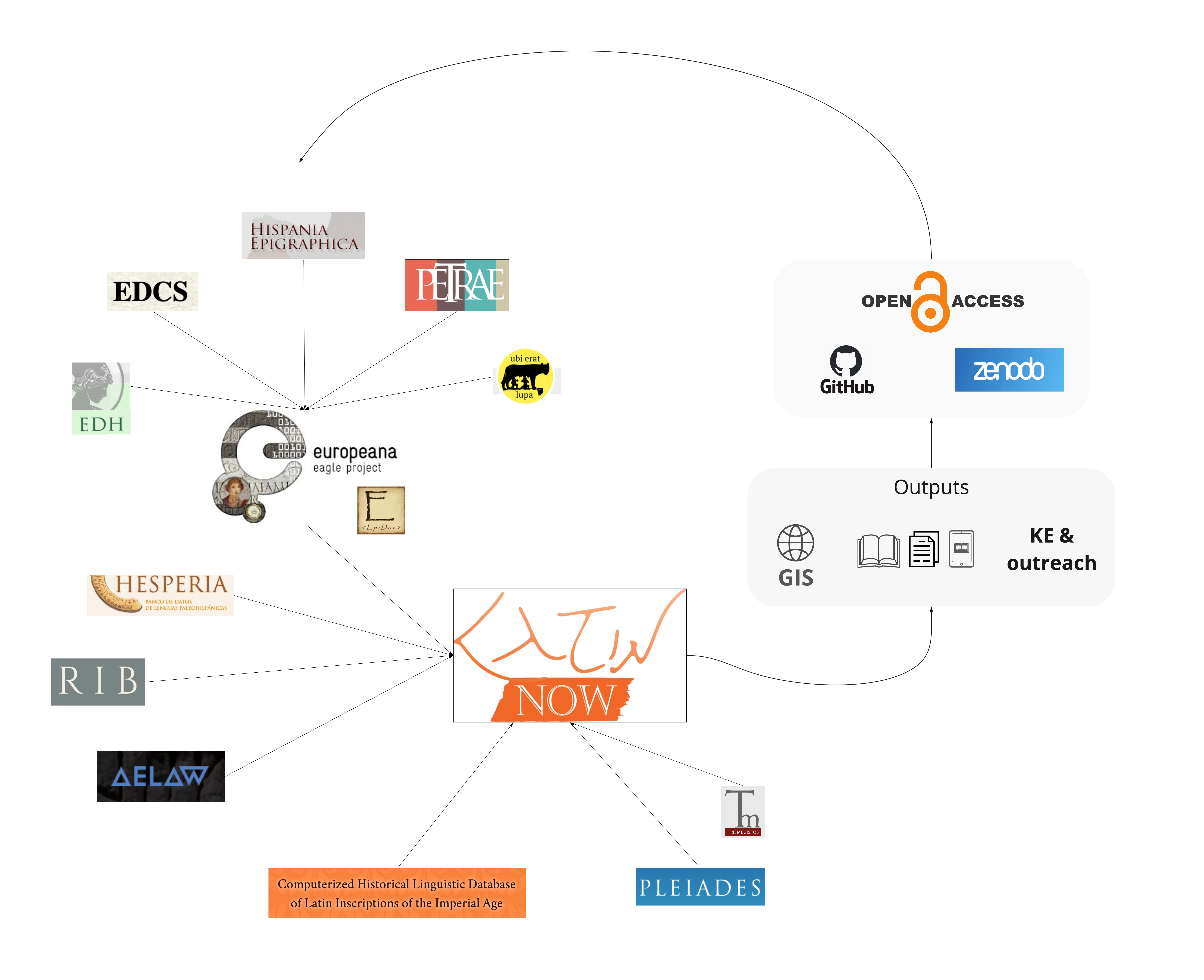
Considering the large geographical and temporal scope of LatinNow, we asked the EAGLE-Europeana network to share their epigraphic data from the north-western provinces. They kindly agreed and that was the start of our core dataset. That meant that we had EDH, EDCS, Hispania Epigraphica, Ubi Erat Lupa and PETRAE, amongst others, all in EpiDoc, while data from RIB is being added directly by Scott. Of course, the different focus and approach of each of these corpora mean that the granularity of encoding is different – e.g. some projects annotate evidence for dating or very detailed provenance information while others are more interested in the text and provide minimal metadata. However, the shared use of the EpiDoc standard and EAGLE’s efforts enabled us to leverage all available metadata and to query records on a scale otherwise impossible.

We gradually started adding our own corpora into the mix – e.g. Gaulish (Gallo-Greek and Gallo-Latin), Raetic and Noric, as well as the spindle whorl collection discussed here. Using the same attributes and vocabularies allows us to query and compare features of these inscriptions alongside those coming from EAGLE and RIB. Simona also worked with Francesca and Alex on picking a set of socio-linguistic attributes, starting from the massive list in the Computerized Historical Linguistic Database of the Latin Inscriptions of the Imperial Age and building on Francesca’s and Alex’s linguistic research on specific regions. After much debate we decided on half-a-dozen most representative and relevant for our provinces (particularly those with relevance for language contact). Mapping these with our more precise coordinates gives us a clearer picture of socio-linguistic processes across the western part of the empire.
Data can be a messy business and has to be curated and analysed with care and understanding of the principles followed in its collection. Differences in encoding, as mentioned above, come from project-specific needs, while differences in, say, bibliographic reference style, may come from national practices, even personal preferences. Another issue can be the files’ date of publication. We noticed some duplication of records between our dataset and the current EDH, which turned out to be a case of EDH having updated those records post-2015 – the date of the EAGLE data transferred to us. Further complications arose from the different approach towards fragmentary texts/objects. While Trismegistos catalogues all parts of a fragment under one identifier, other data providers treat each fragment as a separate item with its own identifier. Each of these issues, and numerous others, had to be addressed with a combination of epigraphic, publishing, encoding and data science experience. Reconciling varying approaches to the recording of our material is no easy task and is not a trivial task.
We, especially Scott and Pieter, worked hard on the improvement of geospatial coordinates, since mapping is a key tool in our research. This involved pouring over publications in an attempt to figure out how to pin down ‘the south-west corner of Don Pedro’s farm’ and trying to work out why different projects had recorded sometimes radically different co-ordinates. It was always important to work out whether ‘dump sites’ had been deployed by projects, i.e. a consistently chosen central location used to place inscriptions whose provenance was not known e.g. beyond a province.

We also spent a lot of time adding to and harmonizing attributes. A starting point for our metadata consolidation was the EAGLE vocabularies for material, object type and text type. The importance of EAGLE’s attempt at reconciling complex terminology in multiple languages from multiple projects cannot be overstated. It has made projects like ours possible and has encouraged the epigraphic community to work with more concertation on the digital future of our field. Currently, there is an effort from both the epigraphy.info and the Linked Pasts community to review and streamline the vocabularies, and build more robust Linked Open Data mechanisms around them. While we wait for this work to be completed, we spent hours debating issues such as: what is a Tafel vs table vs plaque vs tablet vs plate; do we actually need to leverage them with one or two terms, or can we keep them all and still perform meaningful searches and analyses?
But without a doubt the most time-consuming task was deduplication. Projects at the time of the download from EAGLE did not consistently link up their data – e.g. with a Trismegistos ID or similar. As a result, with downloads from multiple different digital epigraphic projects, some of the same objects had as many as half a dozen records. Finding them is easy if they share identifiers, but the majority were not straightforward to find, requiring bibliographical/text comparisons, for example. And ultimately, for a frustratingly large number, time-consuming checking of original publications. Once we have a fully deduplicated dataset, Scott will set in motion ‘The Great Merge’, which will allow the metadata from multiple projects to show under one new merged record, making one set of very rich records for our provinces.
Our metadata efforts are now bearing fruit beyond our own convenience. We are collaborating, for example, with the Michel Feugère at the CNRS Lyon, where he and his team are working on a corpus of inscribed small finds drawn from his Artefacts website. Our taxonomy has been consulted by them, to ensure consistency and compatibility between our data sets.
All of our research outputs will be open access and we follow the FAIR principles of data management for our digital assets. Our final results will be available in Zenodo, GitHub, and as many other repositories as we can find. We are in conversation with our colleagues to work out how best to feed back to them our additions to the data they provided. And, importantly, we will follow the best practice set out by the epigraphic community on standardization and Linked Open Data.
We thank all those projects who have shared data with us and look forward to our linked data future!